
At Google’s annual developer conference, Google I/O, much of the keynote was dedicated to advances in conversational AI.
The segment was split between new capabilities for Google Assistant, which is a conversational AI tool that you can use today, and LaMDA, Google’s research program that’s creating the conversational AI of the future.
Google is making its assistant ever more accessible with quick-access commands that don’t require a wake-word and ‘look and talk,’ where the assistant takes cues from your gaze to know when you’re talking to it. Or her. Or him, depending on how anthropomorphic we wanna be and which voice you choose!
The Google Assistant announcements are small, important, but incremental improvements to the tech and the experience. But LaMDA is much more future-focused.
LaMDA stands for Language Models for Dialog Applications. A language model is a tool for helping computers understand language. And dialog applications are what we build to help users, typically customers, interact with business IT systems to get stuff done using conversation. So LaMDA is super relevant and super interesting to the future of conversational AI.
The key advance that was announced was a new way to ‘prompt’ language models.
In typical conversational AI platforms today, we take a large background language model (like GPT-3 or BERT) and then ‘prompt’ the language models by providing example phrases for each intent that a customer might have when contacting a business. Then when a customer calls or opens a chat session and says what they want help with. The platform uses the language model to figure out which intent best describes the customer’s query based on the prompts we gave it.
The big innovation announced at I/O was the idea of ‘chain of thought’ prompting.
Here, the ‘prompts’ are much more complex. We’re asking the language model to solve a problem. The simple way to do it would be this:
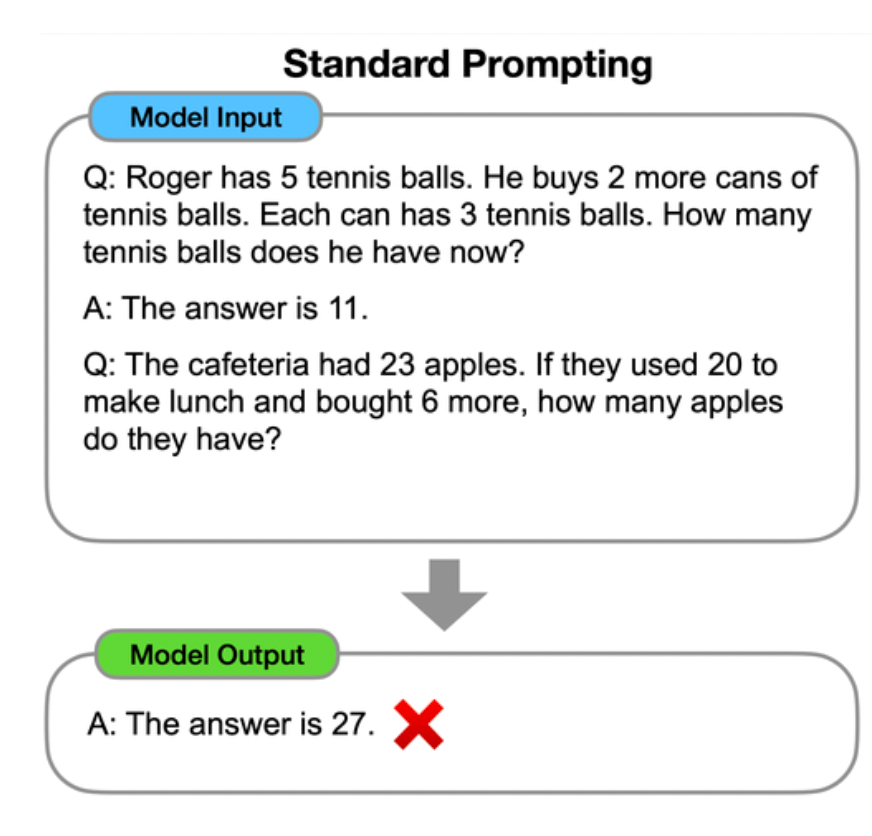
The language model got the wrong answer in this case. But if we prompt it with a more complex answer, which involves breaking down the problem into the stages to complete it, suddenly the results are much more accurate:
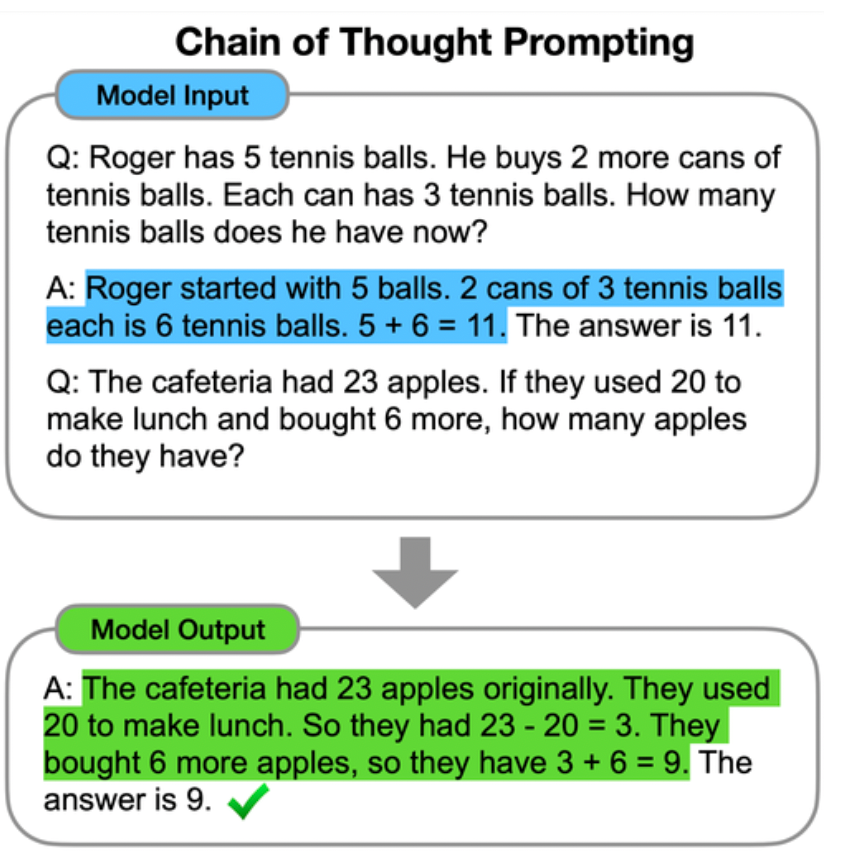
Quite impressive, eh?
It just goes to show how much richness exists in the language models. They’re going beyond language and have learned mathematical and other reasoning concepts we express through language. And if we prompt them in the right way, they can use that knowledge.
Let’s not get carried away. This technology is still in its very early days. But the direction seems pretty clear to me.
Large language models encapsulate much of the richness of language but also many of the simple concepts that we express through language. If we can find a way to ‘prompt’ the models in a way that allows them to apply the model to our task, the results can be quite impressive.
But — and it’s a big but —there are still so many ways in which this technology can and will fail. Prompt it in too simplistic a way, and 23-20+6 = 27. Prompt it right, and you’ll get the correct answer. But what’s the right way to prompt it? What examples should you use? In which areas can conversational AI be successful? Where do we need humans? Where would a different channel, like web, or mobile, be more effective?
Advances in conversational AI will extend the variety of use cases where IVR, IVA, messaging, and chatbot applications can be effective. It will reduce the cost of creating applications. But for the foreseeable future, and I’m talking ten years minimum here, it’s our partnership with AI that will bring the best out of it.
About the Author

Kerry Robinson
VP of Conversational AI
Waterfield Tech
An Oxford physicist with a Master’s in Artificial Intelligence, Kerry is a technologist, scientist, and lover of data with over 20 years of experience in conversational AI. He combines business, customer experience, and technical expertise to deliver IVR, voice, and chatbot strategy and keep Waterfield Tech buzzing.
To receive insights like this in your inbox, sign up to receive Kerry’s weekly newsletter.


